基于Hadoop、Spark與Kafka的淘寶電商大數據推薦系統與情感分析
隨著電子商務的快速發展,淘寶等平臺積累了海量的用戶行為數據和商品評論數據。如何從這些大數據中挖掘有價值的信息,實現個性化推薦和情感分析,成為電商平臺提升用戶體驗和銷量的關鍵。本畢業設計基于Hadoop、Spark、Kafka和Hive等技術,構建一個完整的淘寶電商大數據處理與分析系統,涵蓋商品推薦、評論情感分析、數據可視化及系統服務功能。
一、系統架構與技術選型
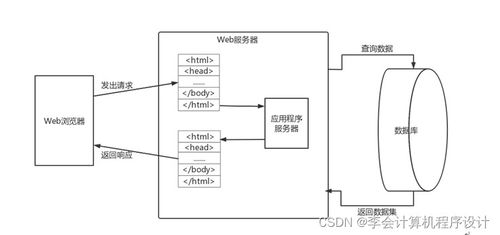
本系統采用分層架構設計,包括數據采集層、數據處理層、數據分析層和應用服務層。
- 數據采集層:利用Kafka作為消息隊列,實時收集淘寶用戶行為數據(如瀏覽、點擊、購買記錄)和商品評論數據。
- 數據處理層:使用Hadoop的HDFS存儲海量數據,并通過Hive進行數據清洗和預處理,構建數據倉庫。
- 數據分析層:基于Spark的MLlib和Spark Streaming實現實時和離線分析。Spark用于商品推薦算法的訓練(如協同過濾、基于內容的推薦),以及評論情感分析(使用自然語言處理技術識別正面、負面情感)。
- 應用服務層:通過Web服務提供推薦結果和情感分析報告,并利用可視化工具(如ECharts或Tableau)展示電商數據趨勢、用戶行為熱圖和情感分布。
二、核心功能模塊
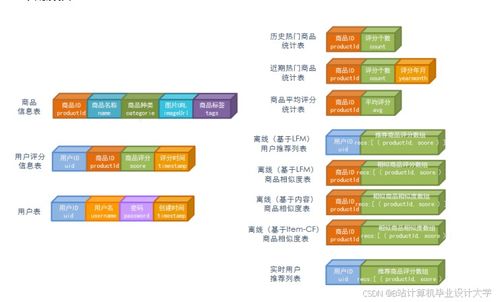
- 淘寶商品推薦系統:基于用戶歷史行為和商品屬性,采用協同過濾和深度學習模型,生成個性化推薦列表。系統能實時更新推薦結果,適應動態用戶偏好。
- 淘寶商品評論情感分析:對商品評論進行情感傾向分析,幫助商家了解用戶反饋,優化產品和服務。使用Spark NLP庫進行文本預處理和情感分類,輸出情感評分和關鍵詞提取。
- 電商推薦系統整合:將推薦與情感分析結合,例如,根據情感分析結果調整推薦權重,優先推薦高評價商品。
- 淘寶電商可視化:通過儀表盤展示用戶行為數據、推薦效果指標和情感分析結果,支持多維度查詢和交互式分析,便于決策者洞察趨勢。
- 計算機系統服務:系統部署在分布式集群上,確保高可用性和可擴展性。使用Docker容器化技術管理服務,并通過監控工具(如Prometheus)實時跟蹤系統性能。
三、實現流程與優勢
實現流程包括數據導入(通過Kafka和Flume)、數據預處理(Hive SQL)、模型訓練(Spark ML)、結果存儲(HBase或MySQL)和前端展示。優勢在于:
- 實時性:Kafka和Spark Streaming支持實時數據處理,提升推薦和情感分析的響應速度。
- 可擴展性:Hadoop和Spark的分布式架構輕松處理TB級數據。
- 準確性:通過多算法融合和情感分析優化推薦精度,提高用戶滿意度。
- 實用性:系統可直接應用于電商場景,幫助平臺提升轉化率和用戶粘性。
四、總結與展望
本系統整合了大數據處理、機器學習和可視化技術,為淘寶電商提供了全面的數據驅動解決方案。未來可擴展更多功能,如引入圖計算優化推薦、集成深度學習模型提升情感分析準確率,或結合云計算服務進一步降低成本。通過本畢業設計,學生可以深入掌握大數據生態系統,為職業生涯奠定堅實基礎。
如若轉載,請注明出處:http://m.uggmaker.com.cn/product/14.html
更新時間:2026-01-09 15:49:10